Venice does not store or log any prompt or model responses on its servers. This is an architectural default, not an opt-in setting.Documentation Index
Fetch the complete documentation index at: https://veniceai-experiment-guides-top-level-tab.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
How requests are processed
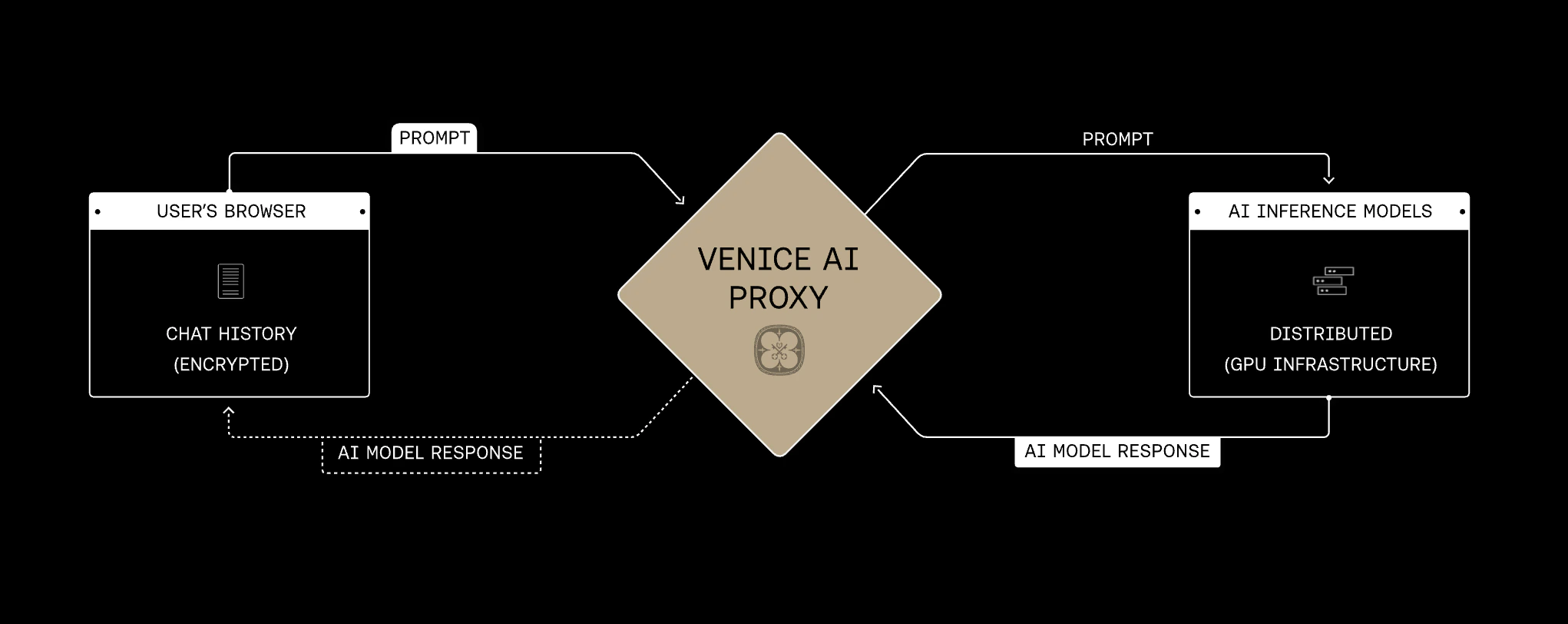
When you send a request to the Venice API:- Your request is transmitted over SSL to Venice’s proxy server
- The proxy routes the request to the model’s inference endpoint. No prompt content is logged at the proxy layer.
- The model processes the prompt in memory and streams the response back
- The prompt and response are purged from memory. Nothing is written to disk.
Private vs Anonymized models
Venice serves models through two infrastructure paths. Private models run on Venice’s GPU fleet using open-source models. The full request stays within Venice’s infrastructure and no third party is involved. Zero Data Retention applies end-to-end. Anonymized models are served by third-party providers (Anthropic, OpenAI, Google, xAI, and others). Venice strips all identifying information before forwarding the request. Venice’s own ZDR still applies - nothing is logged or stored by Venice - but the third-party provider may retain the anonymized request content according to their own policies. See Provider Privacy for details on how each path works and each provider’s retention policies.TEE and E2EE models
Some of our hosted Private models add stronger, cryptographically verifiable protections. TEE models run inside Trusted Execution Environments - hardware-secured enclaves. This adds a verification layer on top of Venice’s standard Zero Data Retention architecture. Clients can verify that a model is running in a genuine TEE with attestation verification - which you can learn about in our TEE & E2EE model guide. E2EE models build on TEE protection by encrypting prompts client-side before they leave your application. Venice relays encrypted data, and only the attested enclave can decrypt it. E2EE models require client-side integration andstream: true; see TEE & E2EE Models for the full protocol.
In the
/models API, TEE and E2EE appear as capabilities on Private models through supportsTeeAttestation and supportsE2EE. The base privacy field remains private.What Venice does not store
- Text prompts and model responses
- Generated images, audio, and video
- Uploaded files and documents
- Conversation history (stored in your browser only)
What Venice does store
Venice retains operational metadata for billing, rate limiting, and platform health. This metadata does not include the content of your prompts or responses. See Data Collection for the full breakdown.Training
Data sent to the Venice API is not used to train or improve any model. For Private models, this is guaranteed by architecture. For Anonymized models, this is based on each provider’s current policies - see the provider policy table.Caching
Some models support prompt caching, which keeps repeated prompt prefixes in GPU memory to reduce latency and cost. Venice considers in-memory caching consistent with zero data retention. Cached data is transient, never written to disk, and automatically evicted when memory is needed.Shared chats
When you share a chat through the Venice web app, the conversation is encrypted in your browser before upload. The encrypted data is stored on Venice servers for 14 days. The decryption key exists only in the share URL - Venice cannot read shared chat content.Verification
Venice is pursuing third-party audits to independently verify its privacy architecture. The guarantees described on this page are architectural: the system is designed so that data is not retained, rather than relying on a policy commitment alone.